|
I am a masters student in Computer Science at New York University and a member of the ML2 Group at CILVR, where I am advised by Prof. He He. Prior to this, I worked as a Research Engineer at Product Labs, IIIT Hyderabad, leading project teams applying research in the domain of object detection/tracking, document querying and speech processing to develop commercially viable products. I also worked as a Research Assistant at Laboratory for Computational Social Systems, IIIT Delhi, solving research problems in the domain of blackmarket-driven social media fraud. I completed my bachelors in Computer Engineering from NSIT, University of Delhi, following which I worked at Microsoft as a Software Engineer in the Office Product Group, where I delivered impactful work for products like Excel, Kaizala and Skype for Business. Email / CV / Google Scholar / Github / LinkedIn / Flashy Website |

|
|
I'm interested in natural language processing, multimodal learning and robust machine learning. My research interests are centered around developing robust and intelligent systems that can solve impactful problems. |
|
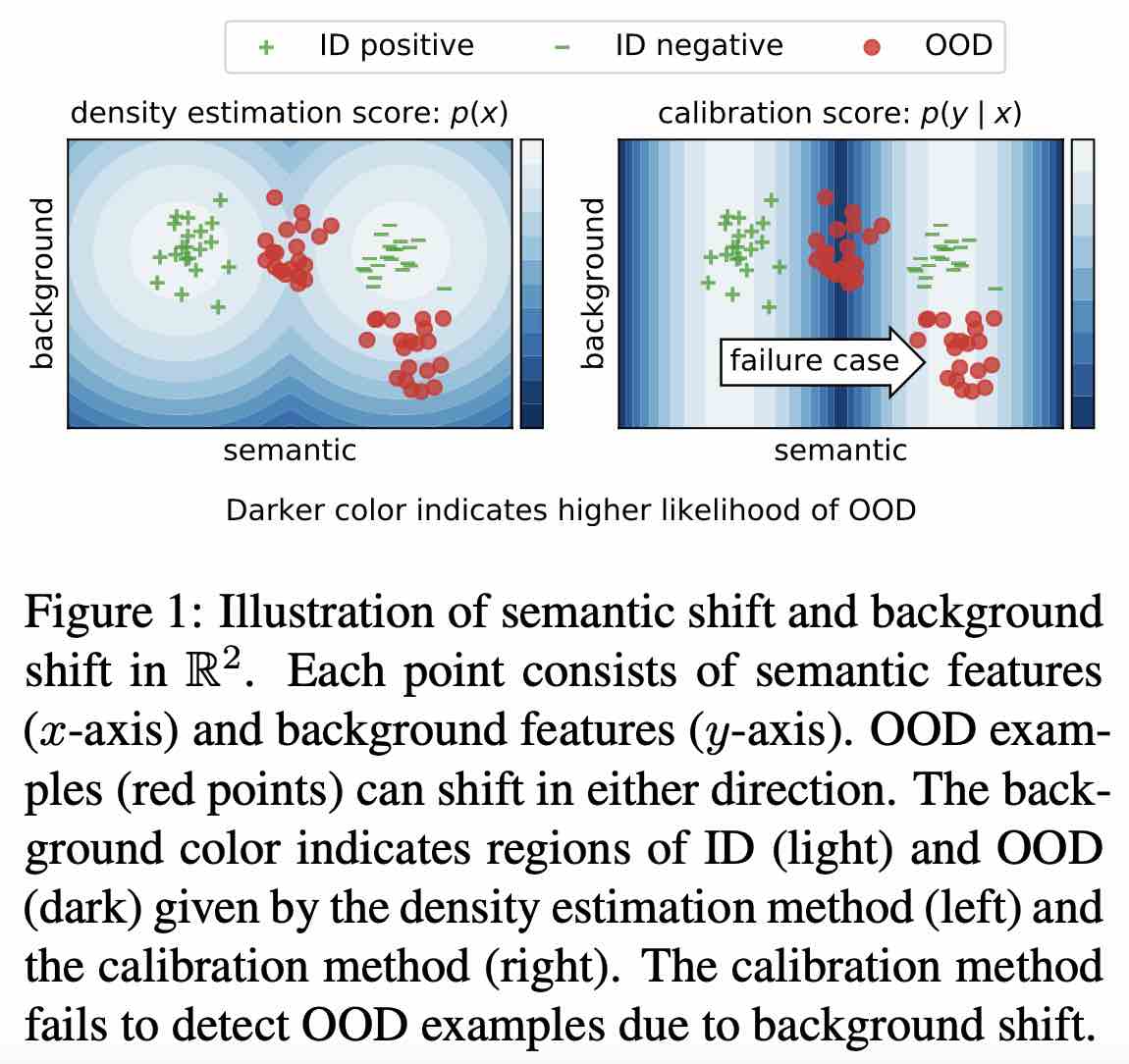
Udit Arora, William Huang, He He Empirical Methods in Natural Language Processing (EMNLP), 2021 Code Categorization of different ID/OOD text dataset pairs based on the type of distribution shift, and evaluation of the OOD detection performance of the two most common detection methods - density estimation and calibration - on these datasets. |
|
Hridoy Sankar Dutta, Udit Arora, Tanmoy Chakraborty International AAAI Conference on Web and Social Media (ICWSM), 2021 Link A multi-platform data repository consisting of artificially boosted (also known as blackmarket-driven collusive entities) online media entities such as Twitter tweets/users and YouTube videos/channels, which are prevalent but often unnoticed in online media. |
|
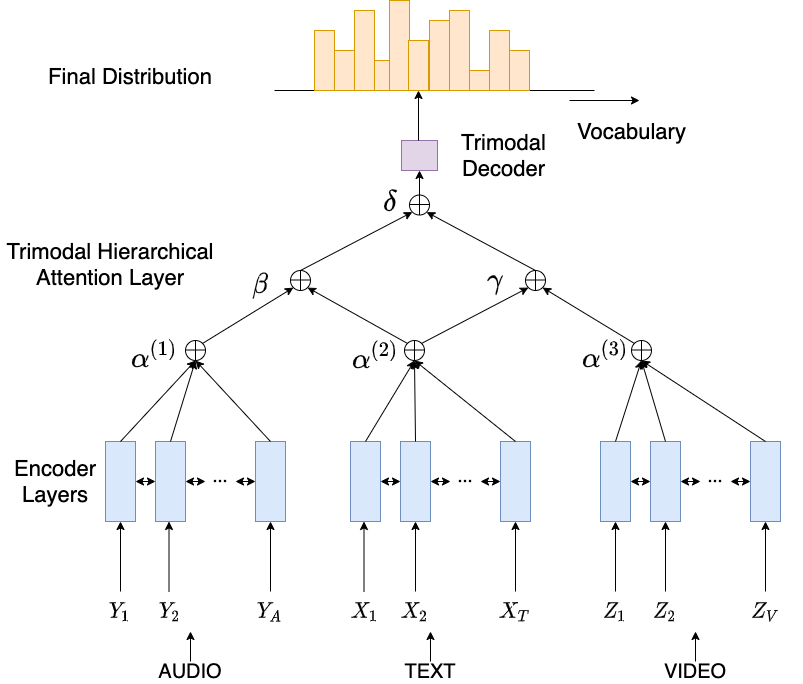
Aman Khullar*, Udit Arora* EMNLP Workshop on NLP Beyond Text, 2020 Code Multimodal summarization by utilizing information from all three modalities of a video and trimodal hierarchical attention. (* = equal contribution) |
|
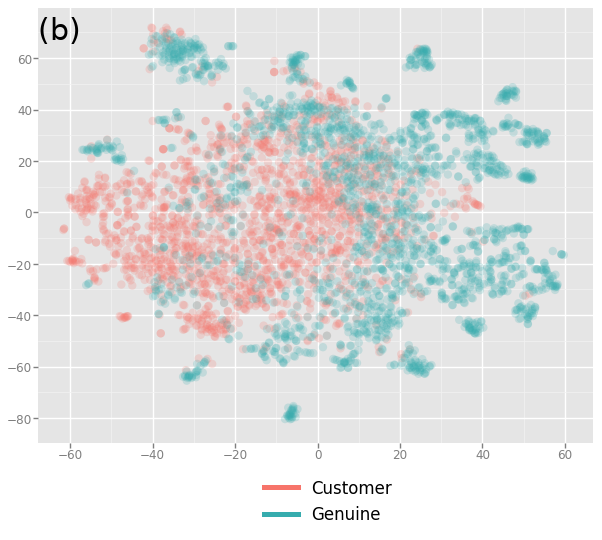
Udit Arora, Hridoy Sankar Dutta, Brihi Joshi, Aditya Chetan, Tanmoy Chakraborty ACM Transactions on Intelligent Systems and Technology (TIST), 2020 PDF | Code and dataset Detection of users involved in blackmarket-driven retweeting activities on Twitter using a multiview learning based approach to encapsulate different views of information about the users. |
|
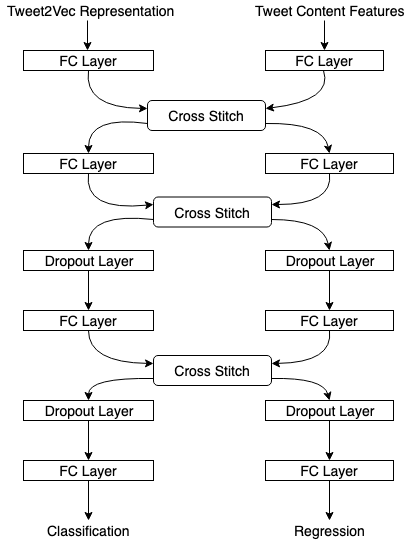
Udit Arora, William Scott Paka, Tanmoy Chakraborty 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM ’19), 2019 Detection of tweets posted on blackmarket services to gain inorganic appraisals - using a multitask learning based framework. |
|
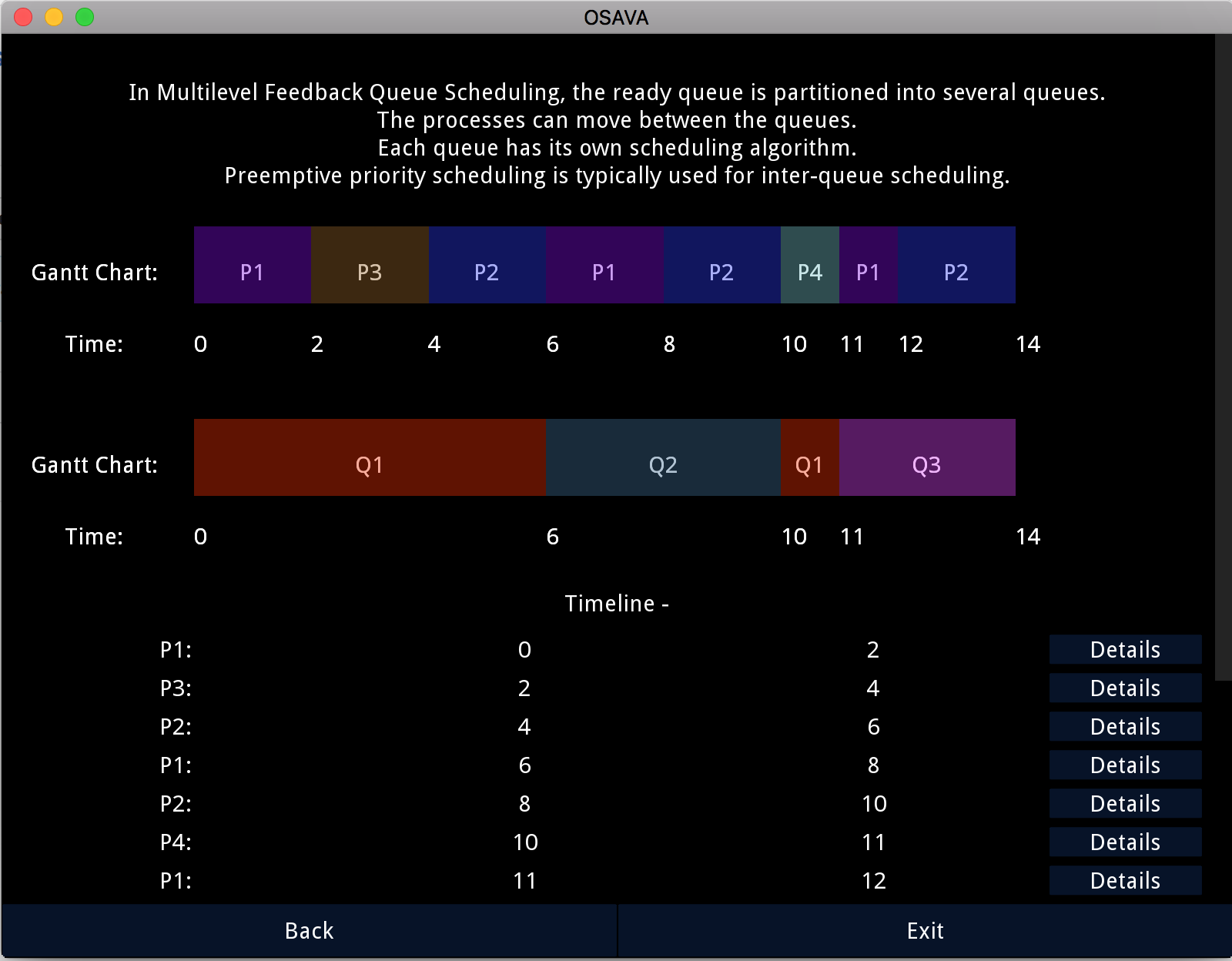
Pinaki Chakraborty*, Udit Arora*, Namrata Mukhija, et. al. Journal of Enginering Education Transformations (JEET), 2019 Code An Android app named Operating System Algorithms Visualization App (OSAVA) to visualize different types of algorithms used in operating systems. It was used to teach a course on operating systems. |

|
Savita Yadav, Pinaki Chakraborty, Prabhat Mittal, Udit Arora Acta Paediatrica, 2018 Parents sometimes show young children YouTube videos on their smartphones. We studied the interaction of 55 Indian children born between December 2014 and May 2015 who watched YouTube videos when they were 6–24 months old. |
|
|